Implementation#
This section distinguishes between the existing proof-of-concept (PoC) implementations used for evaluation and experimentation, and the ongoing work toward a full Host-Orchestrated Multipath I/O (HOMI) reference implementation. The PoC represents a concrete, functional subset of the overall design, while HOMI defines the target system architecture that is currently under active development.
Proof-of-Concept Implementation#
The current PoC consists of a set of functional software components that demonstrate key aspects of accelerator-integrated storage I/O. These components are used to validate feasibility, explore performance characteristics, and exercise device-initiated I/O paths under controlled conditions.
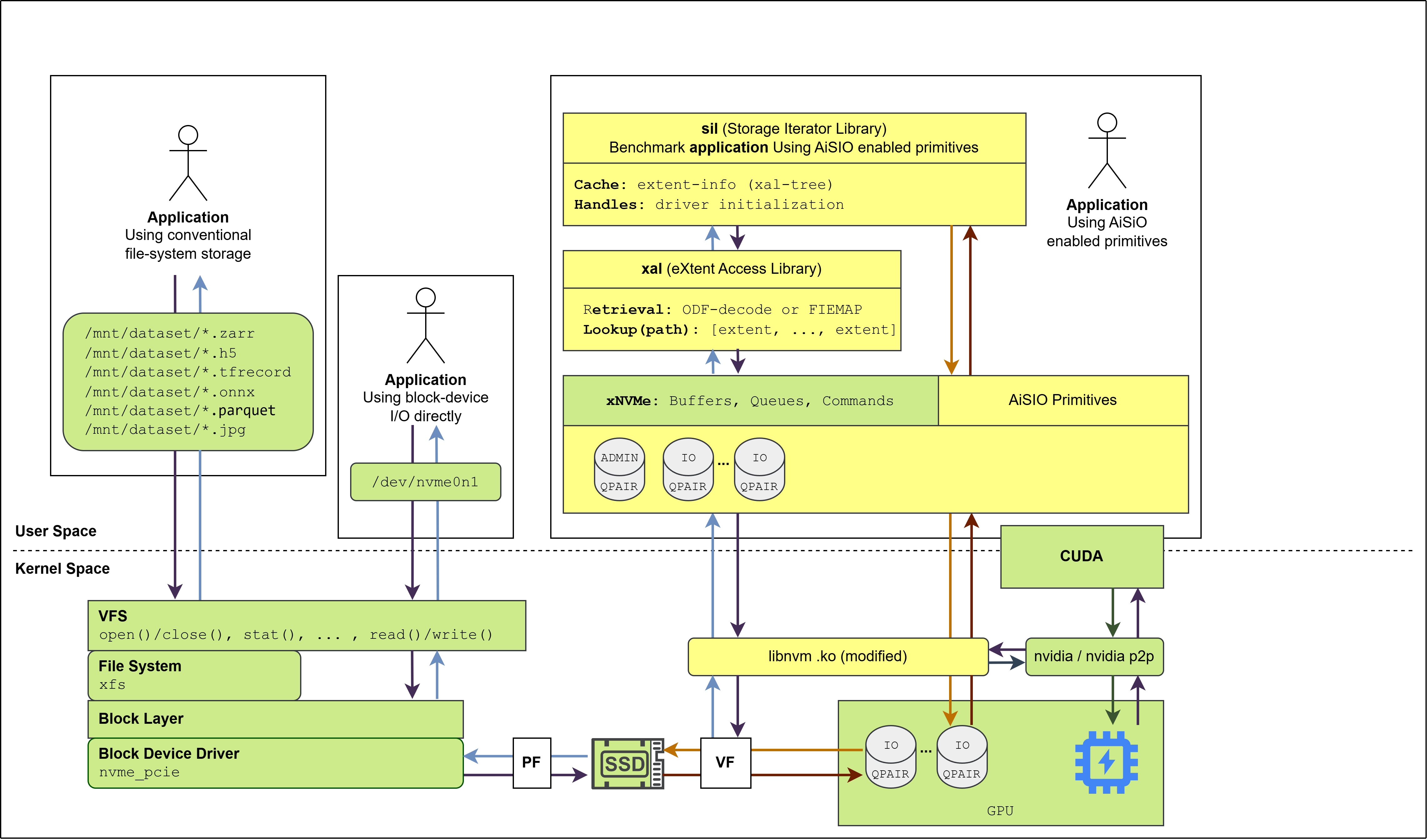
Overview of the initial AiSIO PoC#
The AiSIO PoC demonstrates functionality on Linux systems using:
xNVMe for NVMe command construction and submission across both CPU-initiated and GPU-initiated I/O paths, including invocation directly from CUDA kernels, using libnvm [3] in its BaM-modified form [4] as the underlying PCIe access library.
The NVIDIA GPU driver and its peer-to-peer memory interface for direct DMA between the NVMe controller and GPU device memory.
The XAL metadata decoder for XFS.
The SIL: Storage Iterator Library (now called FIL: File Iterator Library), a benchmark application that iterates over file-based datasets using XAL for extent resolution and exercises both CPU and GPU I/O paths.
The PoC is open-source, reproducible, and interoperates with unmodified XFS.
The PoC relies on hardware-assisted delegation using NVMe Single Root I/O Virtualization (SR-IOV). NVMe Virtual Functions (VFs) are provisioned and assigned statically to initiators. A single host-resident process performs device initialization, queue provisioning, metadata handling, and I/O submission. In this configuration, control-plane and data-path responsibilities are co-located, and no separate persistent host-resident control-plane daemon is present.
Accelerator access in the PoC is realized by assigning an NVMe Virtual Function directly to the accelerator, enabling device-initiated I/O through hardware-isolated queues. This allows multiple initiators to access shared namespaces concurrently, but does not yet exercise dynamic queue management or centralized host orchestration.
The PoC includes early implementations of several HOMI-related components, such as user space NVMe driver extensions, accelerator-accessible I/O queue provisioning, and file system extent extraction used to support file-backed accelerator access. These components are functional but are composed in a reduced form suitable for experimentation rather than as a complete system.
HOMI Reference Implementation (Work in Progress)#
The HOMI reference implementation represents the intended realization of the architecture described in Section Architecture. It extends beyond the current PoC by introducing a host-resident orchestration layer responsible for global coordination across OS-managed, user space managed, and device-initiated I/O paths.
Key elements of the HOMI reference implementation that are under development include a persistent host-resident control-plane daemon, dynamic provisioning and assignment of NVMe queue resources across initiators, centralized caching of file-to-block mappings, and coordinated lifecycle and policy management spanning all I/O paths. Unlike the PoC, the reference implementation is designed to support both software-mediated and hardware-assisted multipath configurations within a unified orchestration framework.
The reference implementation is intended to serve as a stable and extensible platform for exploring host-orchestrated multipath I/O, rather than as a production-ready storage system. Development is ongoing, and future work focuses on incrementally integrating existing PoC components into this broader HOMI framework.
Information about building, installing and managing HOMI is found in the README
file in the homi directory of the AiSIO reference implementation.
uPCIe#
uPCIe is a collection of header-only C libraries for building user space PCIe device drivers. It provides composable, zero-dependency abstractions that cover PCIe device discovery and BAR mapping, DMA-capable memory allocation, and a minimalistic NVMe driver built directly on top of these primitives.
HOMI uses uPCIe as the user space NVMe driver. Being header-only, uPCIe integrates directly into xNVMe — where it is available as a backend for user space NVMe access, as described in the xNVMe uPCIe backend documentation — which in turn is the NVMe layer used by HOMI.
uPCIe includes an optional GPU integration layer that adds CUDA-backed memory management. This enables two distinct I/O modes. In the CPU-initiated P2P mode, the CPU submits NVMe commands while data buffers reside in GPU device memory, with data transferred between the NVMe controller and GPU device memory via peer-to-peer PCIe DMA. In the device-initiated mode, CUDA kernels submit and complete NVMe commands directly, without any CPU involvement.
For device-initiated I/O, xnvme_cuda_queue_create() allocates a GPU-resident
NVMe queue pair in CUDA device memory using cuMemAlloc. The queue pair
structure holds virtual-address pointers to the submission queue (SQ) and
completion queue (CQ) — allocated from the GPU’s DMA-capable heap — along with
a mapping of the NVMe doorbell registers from PCIe BAR0 into the GPU’s address
space. It also tracks the SQ tail, CQ head, phase bit, and a clock-based timeout
derived from the GPU’s SM clock rate.
CUDA kernels call xnvme_cuda_cmd_io() collectively across all threads
in a block. The submission flow proceeds in four stages. First, each thread
enqueues its NVMe command into the SQ using word-by-word volatile pointer
writes, bypassing the per-SM L1 cache so writes reach system DRAM and become
visible to the NVMe DMA engine without waiting for cache eviction. Second, a
__syncthreads() barrier ensures all commands are written before the doorbell
is rung. Third, thread 0 issues a __threadfence_system() fence and writes
the updated SQ tail to the MMIO doorbell register, triggering the controller to
fetch and execute the queued commands. Fourth, each thread polls its CQ entry
using the phase bit to detect completion, with timeout tracked in GPU clock
cycles.
Both modes rely on the NVMe command’s Physical Region Page (PRP) list containing the physical addresses of the data buffer. Obtaining these from CUDA device memory is nontrivial, and is the subject of the following section.
Device Memory Physical Address Resolution via udmabuf-import#
The challenge is that device memory resides in device-local DRAM exposed to the
host through a PCIe Base Address Register (BAR1) aperture, and there is no
standard Linux kernel interface for retrieving its physical mappings from user
space. This has been addressed with a patch to the udmabuf Linux kernel driver,
published as
udmabuf-import. The patch extends
udmabuf with a dma-buf importer role, adding three new ioctl operations:
UDMABUF_ATTACH, UDMABUF_GET_MAP, and UDMABUF_DETACH. These allow
any exported dma-buf file descriptor to be imported into udmabuf. The driver
then performs the DMA mappings internally and returns the resulting physical
address array to the calling process. The mechanism is not specific to CUDA or
NVIDIA hardware; it works with any dma-buf exporter.
For CUDA device memory, the flow is as follows. A CUDA-backed heap is initialized
by allocating device memory with cuMemAlloc, then exporting it as a
dma-buf file descriptor via cuMemGetHandleForAddressRange with the
CU_MEM_RANGE_HANDLE_TYPE_DMA_BUF_FD handle type. This file descriptor
is passed to the dmabuf_attach wrapper in the uPCIe library, which opens
/dev/udmabuf and issues UDMABUF_ATTACH to obtain the page count,
followed by UDMABUF_GET_MAP to retrieve an array of (dma_addr, len)
tuples. These are indexed into a lookup table (LUT) keyed at 64 KiB granularity,
the native page size for NVIDIA GPU device memory, enabling runtime translation
from any device memory virtual address to the corresponding physical address.
xnvmeperf Device-Initiated Benchmarking#
xnvmeperf integrates device-initiated I/O through its cuda-run subcommand.
The host allocates GPU-resident NVMe queue pairs and DMA buffers in CUDA device
memory, builds NVMe commands with PRP lists populated from physical addresses
resolved via the udmabuf-import mechanism described above, and uploads the
commands to the GPU. CUDA kernels then execute in a tight loop: one block per
queue, one thread per queue slot, submitting and completing I/O continuously
without returning to the CPU between rounds. A host-mapped flag signals the
kernels to stop after the configured runtime, at which point per-queue round
counts are read back and used to compute throughput. Sequential and random
access patterns are supported through separate kernel implementations; the
random kernel uses a per-thread linear congruential generator seeded from the
host to produce independent LBA sequences without shared-memory coordination.