Device-initiated I/O: I/O Size Scaling#
In device-initiated I/O, GPU threads are the resource that drives commands, and
those threads compete with compute workloads for GPU resources. The PCIe
bandwidth saturation experiment characterized the transition from IOPS-bound to
bandwidth-bound regimes and the protocol overhead ratio for CPU-initiated P2P.
This experiment examines the same questions under device-initiated I/O by sweeping
I/O size across a wide range, from 512 bytes up to 64 KiB, with queue depth
as the secondary variable. The number of queues, nqueues, is fixed at 1. The
aim is to identify the minimum thread count required to saturate the PCIe link
at each I/O size.
xnvmeperf drives device-initiated I/O via the cuda-run subcommand with
the upcie-cuda backend. With nqueues=1, each CUDA thread handles one
in-flight command, so the total thread count equals queue depth × number of
devices. As I/O size grows, each command transfers more payload bytes, so fewer
in-flight commands are needed to fill the PCIe link. The minimum saturating
queue depth is therefore expected to decrease as I/O size increases, revealing
the thread count required at each I/O size.
Hardware-level PCIe receive bandwidth is collected via DCGM alongside the
application-level payload bandwidth reported by xnvmeperf, and a reference P2P
bandwidth measurement from p2pBandwidthLatencyTest provides the practical
ceiling.
Independent Variables#
Variable |
Parameter Set |
|---|---|
I/O size |
{ 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536 } |
Queue depth |
{ 1, 2, 4, 8, 16, 32, 64, 128 } |
Number of queues |
1 |
Number of devices |
16 |
Total CUDA threads |
queue depth × 16 = { 16, 32, 64, 128, 256, 512, 1024, 2048 } |
Tool and backend |
xnvmeperf (cuda-run) + upcie-cuda |
Metrics Collected#
Metric |
Reported by |
|---|---|
Payload bandwidth (GB/s) |
xnvmeperf |
Total PCIe RX bandwidth (p95, bytes/s) |
DCGM field 1010 via |
Peak P2P bidirectional bandwidth (GB/s) |
|
Environment#
The benchmarks were run on the High-Performance Compute Server. NVMe devices are bound
to user space drivers. The CPU governor is set to performance with turbo
boost and SMT enabled. Each configuration is run five times and results are
reported as arithmetic means.
Execution of the Experiment#
Instructions for running bench_cuda_iosize.yaml are provided in
Experimental Framework.
Results#
Results are presented as PCIe RX bandwidth vs. I/O size, with one line per
queue depth (qdepth ∈ { 1, 2, 4, 8, 16, 32, 64, 128 }). All configurations
use xnvmeperf with the cuda-run subcommand and the upcie-cuda
backend, nqueues=1, and 16 NVMe devices. Total CUDA thread count equals
queue depth × 16. The dashed reference line marks the peak P2P bandwidth from
p2pBandwidthLatencyTest.
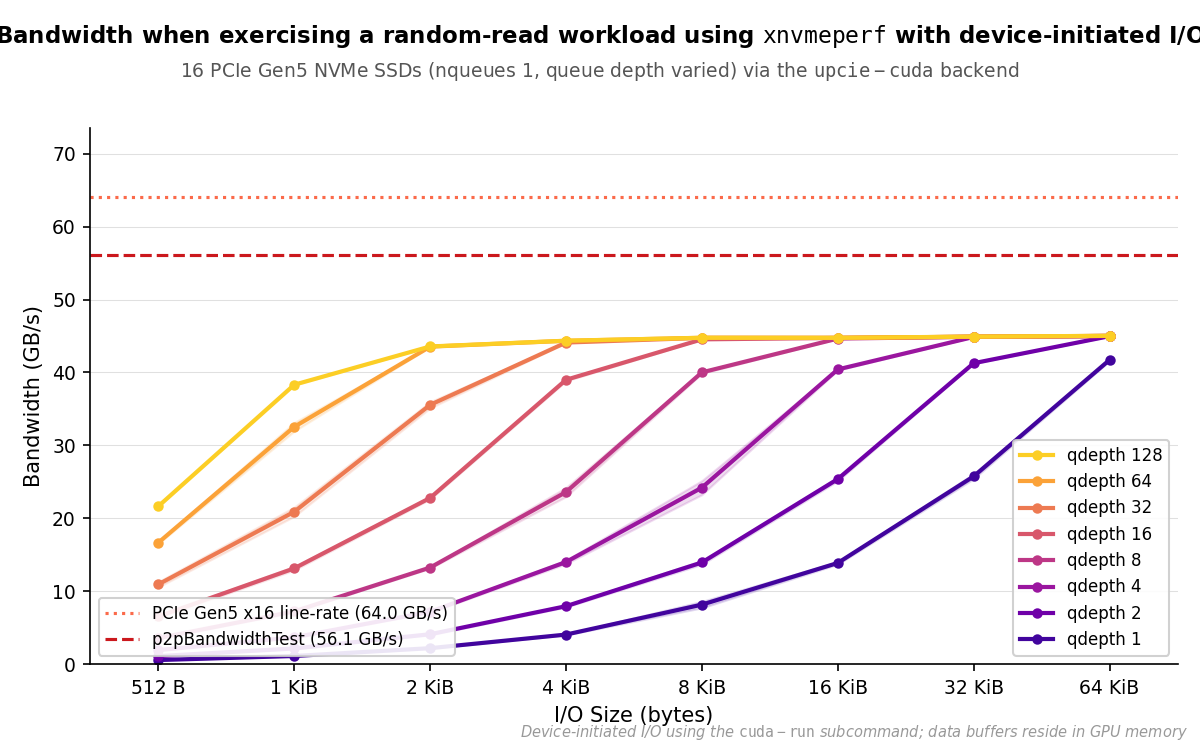
PCIe RX bandwidth vs. I/O size for xnvmeperf (cuda-run), 16 NVMe devices, nqueues=1. The minimum queue depth to saturate the ~45 GB/s practical ceiling drops from >128 at 512 B to 2 at 64 KiB.#
The queue depth required to saturate the PCIe link decreases monotonically as
I/O size grows. At 512-byte I/O, even the maximum configuration of 2048 CUDA
threads (qdepth=128, 16 devices) delivers only 21.6 GB/s. The workload is
constrained by per-device IOPS limits, not by available PCIe bandwidth. As I/O
size increases, each command carries more payload, and the saturation threshold
drops accordingly.
All lines converge at a practical ceiling of approximately 44–45 GB/s, which
falls roughly 80% of the way to the 56.1 GB/s p2pBandwidthLatencyTest
reference. This gap is consistent with the overhead of NVMe command processing
and PCIe protocol framing on top of raw DMA throughput, as characterized in
Results.
The saturation queue depths are:
I/O size |
Min. |
Total CUDA threads |
|---|---|---|
512 B |
> 128 (not reached) |
> 2048 |
1024 B |
> 128 (not reached) |
> 2048 |
2048 B |
64 |
1024 |
4096 B |
32 |
512 |
8192 B |
16 |
256 |
16384 B |
8 |
128 |
32768 B |
4 |
64 |
65536 B |
2 |
32 |
At 64 KiB, a single queue depth of 2, 32 CUDA threads across 16 devices, is
sufficient to sustain ~45 GB/s of storage bandwidth with no CPU involvement
in the command path. qdepth=1 still achieves 41.7 GB/s at this I/O size,
demonstrating that device-initiated I/O can approach the practical link ceiling
with minimal thread-count overhead.
Summary#
The minimum thread count required to saturate the PCIe link decreases monotonically with I/O size. At small I/O sizes the constraint is per-device IOPS rather than link capacity, and even 2048 CUDA threads across 16 devices cannot saturate the link at 512 or 1024 bytes. At 64 KiB, just 32 threads suffice. The practical bandwidth ceiling for device-initiated I/O is approximately 44–45 GB/s, consistent with the ~28% protocol overhead characterized in the preceding bandwidth experiment.