CPU-initiated I/O: Software Abstraction Overhead#
The CPU-initiated I/O: Optimal Parameter Search experiment established the CPU-initiated IOPS ceiling using bdevperf and SPDK. As discussed in the introduction, the software stack between an application and the NVMe controller, e.g., bdev abstraction and driver runtime, imposes overhead that consumes CPU cycles and limits throughput. The AiSIO reference implementation targets this overhead directly, replacing SPDK with the uPCIe backend, which constructs and submits NVMe commands without an intervening driver runtime or intermediate copies.
This experiment isolates the contribution of each abstraction layer by holding hardware and I/O parameters fixed while varying only the benchmark tool and NVMe driver. Stepping from bdevperf through SPDK NVMe Perf to xnvmeperf with the uPCIe backend quantifies the overhead attributable to each layer and shows how much of the CPU-initiated ceiling the uPCIe path can recover. The experiment also introduces the upcie-cuda backend, which places data buffers in GPU device memory and transfers them via P2P DMA, combining the leaner software path with elimination of the host DRAM copy.
The tools under comparison are:
bdevperf: SPDK’s block device benchmark. I/O is issued through SPDK’s bdev (block device) abstraction layer, which interposes between the application and the underlying NVMe driver. The bdev layer provides a uniform interface across storage backends but introduces additional indirection in the I/O path.
SPDK NVMe Perf (
perf): SPDK’s NVMe-level benchmark. Unlike bdevperf, this tool bypasses the bdev abstraction and issues NVMe commands directly through SPDK’s NVMe driver. This eliminates bdev-layer overhead and measures the performance of SPDK’s NVMe driver in isolation.xnvmeperf: xNVMe’s benchmark tool. I/O is issued through xNVMe’s backend-agnostic API, which dispatches to a pluggable backend at runtime. Three backends are exercised in this experiment: the spdk backend, the upcie backend and the upcie-cuda.
I/O Paths#
Understanding what each comparison reveals requires a precise account of the software layers traversed by each tool.
bdevperf submits I/O via spdk_bdev_readv_blocks_with_md(), which
dispatches through the SPDK bdev layer before reaching SPDK’s NVMe driver.
perf submits I/O via spdk_nvme_ns_cmd_read() and related functions,
calling SPDK’s NVMe driver directly without bdev involvement.
xnvmeperf with the spdk backend submits I/O via
spdk_nvme_ctrlr_cmd_io_raw_with_md(), the same SPDK NVMe driver entry point
used for raw command passthrough, reached through xNVMe’s abstraction layer.
Completions are reaped via spdk_nvme_qpair_process_completions(). Like
perf, this path does not involve the SPDK bdev layer.
xnvmeperf with the upcie backend submits I/O through a separate, independent NVMe driver. The upcie backend constructs NVMe submission queue entries directly, enqueues them by writing to MMIO doorbells, and polls the completion queue by reading phase bits, without involving SPDK at any point.
xnvmeperf with the upcie-cuda backend follows the same NVMe command
submission path as the upcie backend, but data buffers reside in GPU device
memory rather than host memory. Buffer allocation uses CUDA device memory via
cuMemAlloc, exported as a dma-buf file descriptor and imported through the
udmabuf-import mechanism to obtain the physical addresses of the GPU memory
pages. These addresses are used to populate the PRP list in the NVMe command,
causing the NVMe controller to transfer data directly to or from GPU memory over
the PCIe fabric via peer-to-peer DMA, without passing through host DRAM.
The following table summarizes the layers traversed by each tool:
Tool |
Benchmark tool |
NVMe abstraction |
SPDK bdev layer |
NVMe driver |
Buffer placement |
|---|---|---|---|---|---|
bdevperf |
bdevperf |
— |
yes |
SPDK |
Host |
perf |
perf |
— |
no |
SPDK |
Host |
xnvmeperf + spdk backend |
xnvmeperf |
xNVMe |
no |
SPDK |
Host |
xnvmeperf + upcie backend |
xnvmeperf |
xNVMe |
no |
uPCIe |
Host |
xnvmeperf + upcie-cuda backend |
xnvmeperf |
xNVMe |
no |
uPCIe |
Device (P2P) |
Comparisons and Their Interpretability#
bdevperf vs. perf#
Both tools are SPDK-native and share the same benchmark design. The only structural difference between them is the presence of the SPDK bdev layer in bdevperf’s path. Performance differences between these two tools can therefore be attributed to the bdev layer in isolation.
perf vs. xnvmeperf (SPDK backend)#
Both tools reach SPDK’s NVMe driver without involving the bdev layer, but they differ in two respects: the benchmark tool itself, and the xNVMe abstraction layer that sits between xnvmeperf and SPDK. Performance differences between these two tools reflect the combined effect of both factors and cannot be attributed to either in isolation.
xnvmeperf (SPDK backend) vs. xnvmeperf (uPCIe backend)#
Both configurations use the same benchmark tool and the same xNVMe abstraction layer. The only structural difference is the NVMe driver: SPDK in one case, uPCIe in the other. Performance differences between these configurations reflect differences in NVMe driver implementation.
xnvmeperf (uPCIe backend) vs. xnvmeperf (uPCIe-cuda backend)#
Both configurations use the same benchmark tool, the same xNVMe abstraction layer, and the same uPCIe NVMe driver. The only structural difference is buffer placement: the upcie backend uses host memory, while the upcie-cuda backend allocates data buffers in GPU device memory and transfers data via peer-to-peer DMA over the PCIe fabric, bypassing host DRAM entirely. Performance differences between these two configurations therefore reflect the effect of P2P buffer placement on the data path, independent of the NVMe driver or benchmark tool.
Experimental Setup#
The experiment was run on the High-Performance Compute Server, the same environment
as the conventional CPU-initiated setup. All NVMe devices are bound to user space
drivers. The CPU governor is set to performance with turbo boost and SMT
enabled. Each benchmark configuration is run five times and results are reported
as arithmetic means.
The independent variables are:
Variable |
Parameter Set |
|---|---|
Tool and backend |
{ bdevperf, perf, xnvmeperf+spdk, xnvmeperf+upcie, xnvmeperf+upcie-cuda } |
Queue depth |
{ 128 } |
I/O size |
{ 512 } |
Number of CPU threads |
{ 1, 2, 3, 4 } |
Number of devices |
{ 16 } |
Results#
This section presents the results of the benchmark tool comparison experiment. The results are structured in two parts. The first steps through the SPDK-based tools: bdevperf, SPDK NVMe Perf, and xnvmeperf with the SPDK backend. This is to quantify the overhead of each layer within the SPDK stack. The second compares the uPCIe backends against the SPDK baseline to show how much of that overhead the leaner driver eliminates, and at what CPU cost the device roofline is reached.
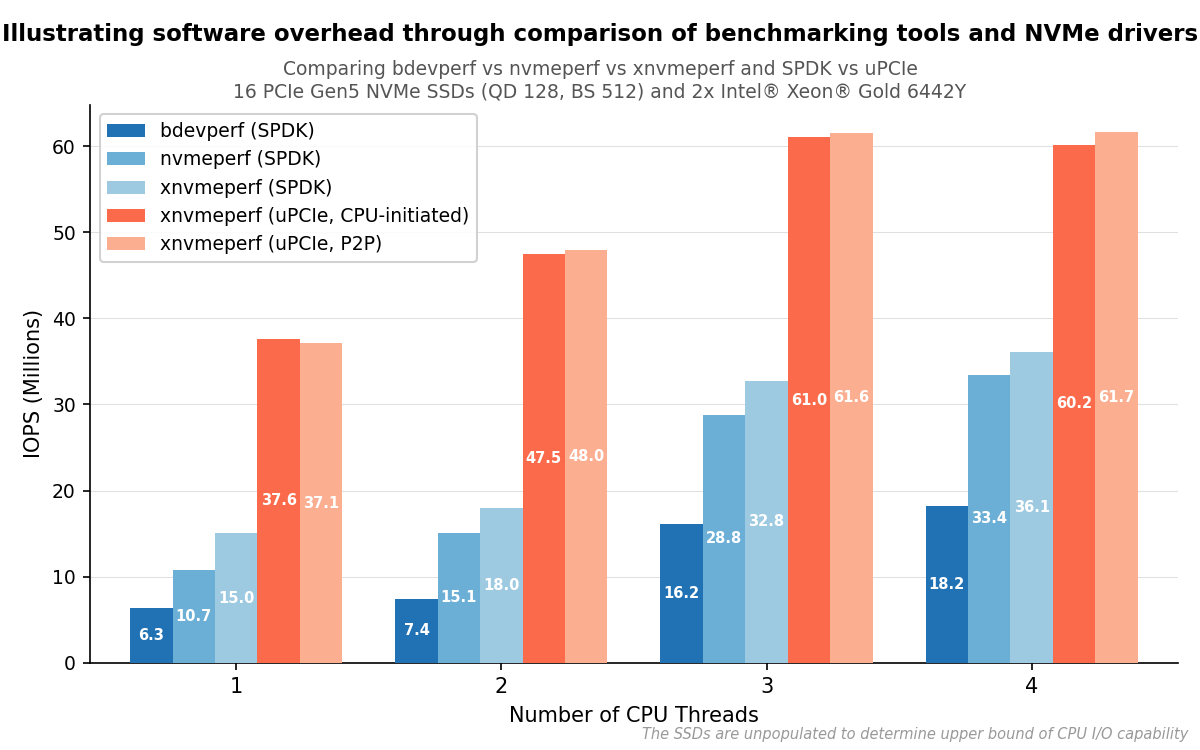
IOPS as a function of CPU thread count for each tool and backend configuration, across 16 NVMe devices at queue depth 128 and 512-byte I/O.#
Stripping Away SPDK Layers#
bdevperf vs. perf#
bdevperf and perf share the same benchmark tool design and the same underlying SPDK NVMe driver, so the difference between them reflects the SPDK bdev abstraction layer alone. perf reaches approximately 70% higher IOPS than bdevperf with one thread, and approximately twice the IOPS with two threads, indicating that the bdev layer imposes substantial cost on this workload. The gap narrows at three and four threads, where bdevperf reaches 16.2 and 18.2 million IOPS respectively, while perf reaches 28.8 and 33.4 million. However, the bdev overhead remains significant across all thread counts tested.
perf vs. xnvmeperf (SPDK Backend)#
xnvmeperf with the SPDK backend reaches approximately 39% higher IOPS than perf with one thread, and approximately 18% higher with two threads. As described above, this comparison is confounded: both the benchmark tool and the xNVMe abstraction layer differ simultaneously, and the result cannot be attributed to either factor alone.
A known contributor on the tool side is that perf performs per-I/O latency
tracking on the hot path. On every submission, it calls spdk_get_ticks() to
record a timestamp, and on every completion it calls spdk_get_ticks() again
to compute the elapsed time, then updates per-queue minimum, maximum, and total
TSC accumulators, and optionally records the sample in a histogram. In addition,
spdk_get_ticks() is called on every iteration of the polling loop in
work_fn. spdk_get_ticks() maps to rdtsc, a non-trivial instruction
that cannot be freely reordered; at tens of millions of IOPS the cumulative cost
of issuing it twice per I/O plus once per poll iteration becomes measurable.
Removing these calls from perf yields approximately 20% higher IOPS at one
thread, narrowing the gap to xnvmeperf to approximately 16%. The improvement
is substantially smaller at two threads (~2%). One possible explanation is that
SMT hides part of the rdtsc cost: when one hardware thread stalls on the
instruction, the other can continue making progress, partially absorbing the
latency rather than paying it in full. Even with latency tracking removed,
xnvmeperf remains ahead, indicating that tool design differences beyond
latency tracking also contribute to the result.
At three and four threads, xnvmeperf with the SPDK backend reaches 32.8 and 36.1 million IOPS respectively, still well below the 61.7 million IOPS device roofline. Across all thread counts, the SPDK-based tools collectively demonstrate that layered software overhead accumulates: removing layers yields meaningful gains at each step, but the combined overhead of the SPDK stack places a ceiling that more threads alone cannot overcome.
Replacing the SPDK Driver with uPCIe#
Since all configurations in this section use xnvmeperf, backends are referred to by name alone for brevity.
With the benchmark tool and xNVMe abstraction layer held constant, the upcie
backend reaches approximately 2.5 times the IOPS of the spdk backend across
both thread counts. As noted above, this comparison reflects differences in NVMe
driver design, including the abstraction layers within each driver, rather than
the xNVMe abstraction layer, which is held constant across both configurations.
The spdk backend relies on SPDK, which routes completions through
spdk_nvme_qpair_process_completions operating within SPDK’s own runtime.
The upcie backend relies on uPCIe, which uses a leaner implementation that
polls the completion queue directly by reading phase bits and writes doorbells
through direct MMIO, without an intervening runtime layer. A contributing factor
is that SPDK performs significantly more memory operations per I/O: it copies
the 64-byte command into an internal request structure, clears approximately
315 bytes of request state via memset, and copies the payload metadata
before the command reaches the submission queue. uPCIe avoids these intermediate
copies, referencing the command directly and writing it once to the submission
queue.
At three CPU threads, both upcie and upcie-cuda reach approximately 61 million IOPS, meeting the device roofline established in the CPU-initiated I/O: Optimal Parameter Search experiment. Adding a fourth thread brings no further improvement, confirming that the device, not the CPU, is the bottleneck at three threads. By contrast, xnvmeperf with the SPDK backend reaches only 36.1 million IOPS at four threads, never approaching the ceiling within the thread counts tested.
The upcie-cuda backend produces results within approximately 1% of the upcie backend across all thread counts. Since the two backends share the same NVMe driver and differ only in buffer placement, this indicates that routing the data path through P2P DMA to GPU device memory does not measurably affect the IOPS achieved by the NVMe command submission path under these conditions.
Summary#
Three findings emerge from this experiment. First, the SPDK bdev abstraction layer imposes substantial cost: bypassing it with SPDK NVMe Perf yields approximately 70% higher IOPS at one thread. Second, uPCIe reaches approximately 2.5 times the IOPS of SPDK when the benchmark tool and xNVMe layer are held constant, a result that can be attributed to uPCIe’s leaner command path and avoidance of intermediate memory copies. Third, and most directly relevant to the AiSIO design, routing data through P2P DMA to GPU device memory does not measurably affect command throughput: the upcie-cuda backend matches the upcie backend within measurement variance, validating a core assumption of the AiSIO P2P architecture.
Notably, the upcie and upcie-cuda backends achieve approximately 37 million IOPS with a single CPU thread and approximately 47 million IOPS with two threads across 16 devices. At three threads, both backends reach the device roofline of 61.7 million IOPS and adding a fourth thread brings no further improvement, thus confirming device saturation. The CPU-initiated I/O: Optimal Parameter Search experiment required 8 physical cores to reach the same ceiling; the uPCIe path reaches it with three CPU threads, using fewer than half the cores, reflecting the reduced per-command overhead of the leaner driver. These results motivate the CPU-Initiated P2P I/O: PCIe Bandwidth Saturation experiment that follows, which examines how much of the available link capacity the upcie-cuda path actually uses.