Architecture#
Accelerator-integrated Storage I/O (AiSIO) architectures are characterized by the coexistence of multiple I/O paths within a single system, spanning conventional OS-managed storage stacks, host-resident user space frameworks, and device-initiated execution on accelerators. These architectures are designed to enable high-performance data access without sacrificing compatibility with existing file systems, applications, and operating-system storage abstractions. Rather than replacing established OS storage mechanisms, AiSIO focuses on controlled sharing of storage resources and coordinated operation across heterogeneous initiators.
While the architectural principles discussed in this section are not inherently tied to a specific operating system, practical realization of AiSIO systems imposes several non-negotiable requirements on the underlying OS. First, the operating system must be supported by accelerator and device vendors, including the availability of production-quality GPU and accelerator drivers that enable peer-to-peer DMA and low-level device interaction. Second, the OS must expose a sufficiently transparent and extensible NVMe storage stack, allowing system software to reason about controller ownership, queue management, and PCIe function boundaries. Finally, the OS must permit the construction of software-mediated solutions that combine kernel and user space components, enabling rapid iteration and experimentation with alternative I/O paths. Among contemporary operating systems, Linux uniquely satisfies these requirements at scale, and therefore serves as the reference platform for the architectures and implementations described in this work.
AiSIO designs adopt a structural separation between control-oriented responsibilities and high-bandwidth data-path execution. Metadata management, protection enforcement, and system coordination remain associated with the operating system, while accelerators participate in data-path execution using mechanisms suited to parallel data movement. This separation allows each processing unit to operate in its area of strength, while preserving the safety and correctness guarantees that applications and file systems depend on.
I/O Path Taxonomy#
To reason about how AiSIO system architectures support multipath coexistence, we characterize I/O paths along three independent axes: infrastructure, initiator, and buffer placement.
Infrastructure describes which software layer owns the NVMe driver and manages the controller’s queues.
Kernel managed: the kernel NVMe driver performs controller initialization, queue allocation, command submission, and completion handling. The kernel retains full control over device management, file system integration, and protection enforcement.
User space managed: a user space NVMe driver performs these responsibilities directly from user space. This eliminates kernel transitions, interrupt overhead, and block-layer processing, but requires OS-provided abstractions (block devices, scheduling, isolation) to be rebuilt in the user space runtime or foregone entirely.
Initiator describes which processing entity constructs and submits NVMe commands.
CPU-initiated: software executing on the host CPU constructs NVMe submission queue entries, populates data transfer descriptors (PRPs or SGLs), and writes doorbell registers. This applies to both kernel managed and user space managed infrastructure.
Device-initiated: software executing on a PCIe-attached accelerator (such as a GPU) constructs and submits NVMe commands from device-resident driver code. Host-side software remains responsible for device initialization, queue provisioning, and metadata resolution, but the accelerator drives the data path independently once the queues are established.
Buffer placement describes where data buffers and queue structures reside, and determines whether peer-to-peer (P2P) DMA (see PCIe) is involved.
Host memory: data buffers reside in host DRAM. The NVMe controller performs DMA to and from host memory. When an accelerator needs the data, a separate copy from host memory to device memory is required.
Device memory: data buffers reside in accelerator-accessible memory, typically GPU BAR space. The NVMe controller transfers data directly to or from the accelerator over the PCIe fabric via P2P DMA, bypassing host DRAM entirely. Queue structures may also reside in device memory when the accelerator must access them directly.
These axes are independent. The following table summarizes how existing and AiSIO system architectures map onto the three axes:
Components |
Infrastructure |
Initiator |
Buffers |
|---|---|---|---|
pread, libaio, io_uring |
Kernel |
CPU |
Host |
SPDK |
User space |
CPU |
Host |
xNVMe/uPCIe |
User space |
CPU |
Host |
GDS |
Kernel |
CPU |
Device |
io_uring + dma-buf |
Kernel |
CPU |
Device |
xNVMe/uPCIe + CUDA/dma-buf |
User space |
CPU |
Device |
xNVMe/uPCIe + ROCm/dma-buf |
User space |
CPU |
Device |
BaM, SCADA |
User space |
Device |
Device |
xNVMe/uPCIe + CUDA (device-resident) |
User space |
Device |
Device |
The conventional kernel paths occupy the top-left corner: kernel managed, CPU-initiated, host memory. SPDK and xNVMe/uPCIe move the infrastructure to user space while remaining CPU-initiated with host memory buffers; benchmarks comparing these are presented in CPU-initiated I/O: Software Abstraction Overhead. GDS changes buffer placement to device memory while remaining kernel managed. The remaining rows represent the AiSIO system architectures described in the following sections, which combine device memory, user space or kernel infrastructure, and (in the device-resident case) device-initiated I/O.
The Coexistence Problem#
The coexistence problem arises from the infrastructure axis. On Linux, a PCIe function can be bound to only one driver at a time. When the kernel NVMe driver owns a function, no user space driver can access it, and vice versa. This means that kernel managed and user space managed I/O paths cannot operate on the same NVMe controller simultaneously through the same PCIe function. Device-initiated I/O inherits this constraint, since it relies on user space infrastructure to provision queues and manage the controller.
As a consequence, running multiple infrastructure types against a single NVMe controller requires either hardware support for partitioning at the PCIe function level (such as SR-IOV, which exposes multiple independent functions from a single physical device) or a software architecture that takes exclusive ownership of the function in user space and re-exports a block device interface back to the kernel (such as ublk). Without one of these mechanisms, the system must choose a single infrastructure type per controller, forgoing multipath coexistence.
AiSIO System Architectures#
The following subsections describe three P2P system architectures within the AiSIO class, realized as open-source alternatives to the proprietary and academic systems described in the introduction. All three use peer-to-peer (P2P) DMA to transfer data directly between the NVMe controller and accelerator memory over the PCIe fabric, bypassing host DRAM. They share a common foundation in upstream and open-source components (io_uring, dma-buf, xNVMe, and uPCIe) and differ in which entity initiates I/O and which software layer manages the NVMe command path.
Notably, the same xNVMe and uPCIe components also support conventional CPU-initiated I/O with host memory buffers. Benchmarks demonstrate that this configuration outperforms the current state-of-the-art in user space I/O (SPDK) (see CPU-initiated I/O: Software Abstraction Overhead). This is a direct consequence of xNVMe’s design: by abstracting the NVMe command path behind a unified API, xNVMe allows applications to switch between I/O paths (kernel managed, user space managed, or device-initiated, with host or P2P buffers) without modifying application code. Different paths enable different optimizations, and the choice can be made at deployment time rather than at development time.
CPU-Initiated I/O with P2P Memory and Kernel Infrastructure#
The host CPU constructs and submits NVMe commands through the kernel storage stack using io_uring. Data buffers reside in GPU memory, exported as dma-buf objects and imported into the kernel for use as I/O targets. The kernel NVMe driver populates PRPs or SGLs with physical addresses in GPU BAR space, causing the NVMe controller to issue PCIe Memory Read or Write TLPs directed at the GPU rather than at host memory.
Queue pairs are allocated in host memory and managed entirely by the kernel NVMe driver. The kernel retains full control over command lifecycle, device management, and file system integration. The P2P data path is established through composable, upstream kernel interfaces (dma-buf for GPU memory sharing and io_uring for asynchronous NVMe command submission) without requiring proprietary driver modifications.
CPU-Initiated I/O with P2P Memory and User-Space Infrastructure#
The host CPU constructs and submits NVMe commands through a user space NVMe driver. xNVMe provides unified NVMe command construction and submission, while uPCIe manages PCIe resource access from user space. Data buffers reside in GPU memory, and dma-buf is used to establish P2P mappings that expose GPU BAR addresses to the user space driver. The driver constructs NVMe commands with PRPs or SGLs pointing to these GPU physical addresses, and the NVMe controller transfers data directly to or from GPU memory via P2P DMA.
Queue pairs are allocated in host memory and managed by the user space driver. By operating outside the kernel, this path eliminates kernel transitions, interrupt overhead, and block-layer processing. The trade-off is that the kernel no longer mediates access to the NVMe device: queue isolation, P2P memory safety, and coexistence with OS-managed storage must be handled by the user space runtime or by a host-resident control plane such as HOMI.
Device-Initiated I/O with P2P Memory and User-Space Infrastructure#
The accelerator itself constructs and submits NVMe commands from GPU-resident driver code. As in the CPU-initiated user space configuration, xNVMe and uPCIe handle device initialization, queue provisioning, and P2P setup on the host. The key difference is in where the queue pairs reside and who drives the data path.
Queue pair memory (submission queues, completion queues, and associated structures) is allocated in GPU memory via dma-buf, making it directly accessible to the device-resident NVMe I/O driver. The host provisions these queues and registers them with the NVMe controller, but the GPU subsequently operates on them independently: constructing submission queue entries, populating PRPs or SGLs referencing GPU-local data buffers, and writing doorbell registers to trigger command processing. Completions are polled directly by the GPU from completion queue entries residing in its own memory.
Data buffers likewise reside in GPU memory with P2P mappings established through dma-buf. The entire submission-transfer-completion cycle proceeds over the PCIe fabric between the GPU and the NVMe controller. The host CPU is involved only in control-plane operations: queue provisioning, file-to-block metadata resolution, and error recovery.
Host Orchestrated Multipath I/O (HOMI)#
Host Orchestrated Multipath I/O (HOMI) is a reference implementation that addresses the coexistence problem described above. Rather than forcing a choice between I/O path classes, HOMI enables OS-managed, user space managed, and device-initiated paths to operate concurrently on the same NVMe controller.
The term host orchestrated reflects a deliberate architectural choice. The host retains responsibility for global coordination, metadata management, and policy enforcement, while enabling accelerators to participate directly in data-path execution. HOMI resolves the driver exclusivity constraint through two strategies: software-mediated multiplexing via ublk [11], and hardware-assisted delegation via SR-IOV. Both are described in the subsections below.
A foundational component of HOMI is a host-resident daemon that centralizes control-plane responsibilities shared across all I/O paths. This daemon is responsible for device discovery and initialization, NVMe control operations, and the extraction and caching of file-extent information from the host file system. It exposes interfaces through which user space processes and accelerators can obtain access to NVMe resources, including handles required to establish I/O queue pairs for direct command submission.
Accelerators cannot interact directly with kernel metadata structures or perform pathname resolution. HOMI therefore extracts file extent information on the host and makes it available through controlled interfaces, allowing accelerators to translate file offsets into physical block ranges without kernel involvement on the data path.
HOMI is intentionally scoped as a reference implementation. It focuses on exposing and coordinating multiple I/O paths rather than on providing a complete storage solution or introducing new file system semantics. Design choices favor explicitness and observability over generality, allowing the impact of architectural decisions to be studied in isolation.
HOMI via Software-Mediated Multipath (ublk)#
In its software-mediated configuration, HOMI realizes multipath I/O using a user space block interface based on ublk. In this mode, the NVMe controller is initialized and managed by a user space NVMe driver under host control, rather than by the operating system kernel. This places both the control plane and the data plane for the storage device in user space, while preserving a conventional block-device interface toward the kernel.
The user space NVMe driver performs full controller bring-up and administrative operations, and provisions I/O queue pairs for multiple consumers. One set of queues is dedicated to servicing I/O requests originating from the kernel through the ublk interface, enabling OS-managed file systems and applications to operate without modification. These queues reside in host memory and are used for CPU-initiated I/O.
In addition to kernel-facing paths, the same user space driver provisions I/O queues for other user space processes that require direct access to the NVMe device. This allows high-performance user space storage frameworks to coexist with OS-managed I/O paths, ensuring that no single process monopolizes device ownership and that multiple user space consumers can be supported concurrently.
In parallel, the user space driver provisions additional I/O queue pairs that reside in accelerator-accessible memory and are reserved for device-initiated I/O. These queues are used exclusively by accelerators to submit NVMe commands directly, allowing data-path execution to bypass host memory and CPU involvement.
Queue ownership is static for the lifetime of the system configuration. Kernel I/O paths, user space processes, and accelerator-initiated I/O paths do not share queues, and none can access the queue resources of another. Concurrency is provided by the NVMe controller’s native support for multiple queue pairs, eliminating the need for software arbitration on the data path.
This configuration requires no specialized hardware support and allows AiSIO systems to operate on commodity platforms. The trade-off is that queue provisioning, isolation, and coordination across kernel, user space, and device initiators are implemented entirely in software, placing greater responsibility on the host-resident user space control plane.
HOMI via Hardware-Assisted Delegation (SR-IOV)#
When supported by the NVMe device and platform, HOMI can realize host-orchestrated multipath I/O with hardware assistance via Single Root I/O Virtualization (SR-IOV). In this configuration, the NVMe controller exposes multiple PCIe functions that share the same namespaces while providing independent I/O queue resources.
As in the software-mediated configuration, HOMI retains responsibility for global orchestration, system coordination, and file system integration. The host remains the sole authority for device discovery, lifecycle management, and policy enforcement. However, SR-IOV shifts responsibility for I/O queue isolation and arbitration from software into the NVMe controller hardware.
In the SR-IOV configuration, the Physical Function (PF) is host-managed and retains administrative control over the device. Virtual Functions (VFs) are created and assigned to different initiators, including accelerators and, when required, user space processes. Each VF provides an independent operational interface with its own set of I/O queues, BAR mappings, and interrupt resources, while all functions continue to access the same underlying namespaces.
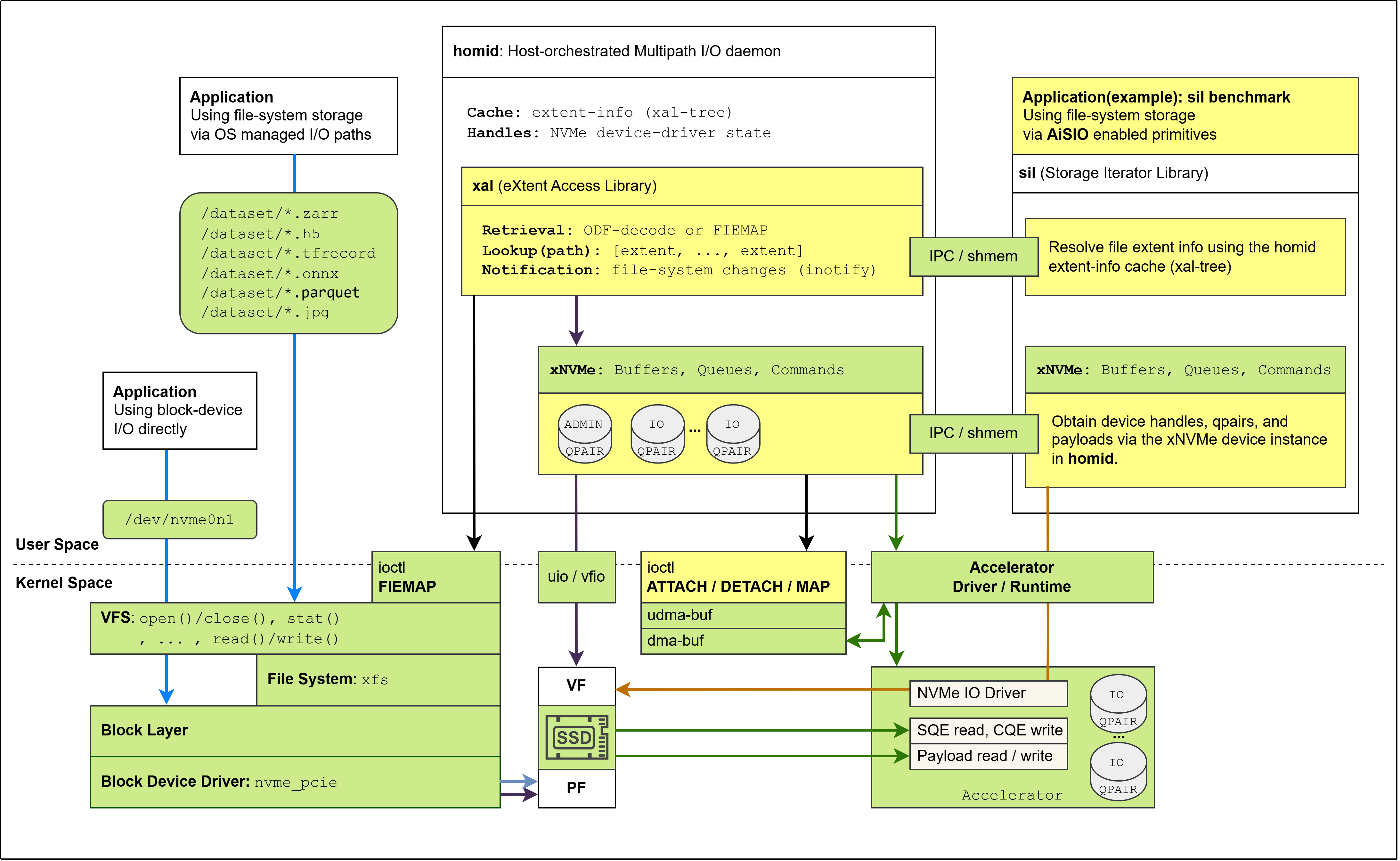
Overall system architecture showing data flow between components.#
This hardware-level partitioning allows kernel managed I/O paths, user space processes, and device-initiated I/O paths to coexist without sharing queue resources or requiring host-mediated queue arbitration on the data path. From the perspective of each initiator, the assigned VF behaves as a dedicated NVMe endpoint, simplifying driver logic and reducing cross-path interference.
Despite this delegation, HOMI remains essential to the architecture. The host control plane continues to manage administrative operations, coordinate file system metadata, maintain the file-extent cache, and handle error detection and recovery. SR-IOV therefore complements HOMI by reducing software overhead on the data path, rather than replacing host orchestration.
Compared to software-mediated multipath, SR-IOV improves isolation and reduces runtime coordination costs, but introduces hardware dependencies and limits flexibility in queue allocation. As a result, it represents an alternative realization of the same architectural principles, rather than a fundamentally different design.