CPU-Initiated P2P I/O: PCIe Bandwidth Saturation#
The CPU-initiated I/O: Software Abstraction Overhead experiment showed that the upcie-cuda backend matches upcie in IOPS within measurement variance, confirming that routing data through P2P DMA to GPU device memory does not measurably affect command throughput. Both preceding experiments were conducted at 512-byte I/O, where each command carries so little data that the PCIe link operates far below capacity even at tens of millions of IOPS. The bottleneck is how fast commands can be submitted and completed, not how much data the link can carry. At larger I/O sizes the bottleneck shifts: as each command carries more payload, the PCIe link itself becomes the limiting factor. The question this experiment asks is how few CPU resources and devices are required to reach that point.
This experiment fixes CPU threads at 1 and devices at 4, then sweeps I/O size
across three points (512, 4096, and 8192 bytes), measuring both the payload
bandwidth reported by xnvmeperf and the total PCIe receive traffic observed by
DCGM at the GPU endpoint. The gap between the two reveals the share of the link
consumed by NVMe and PCIe protocol traffic rather than payload. A reference peak
P2P bandwidth from p2pBandwidthLatencyTest establishes the practical ceiling
of the link under sustained P2P transfers.
Independent Variables#
The experiment fixes all parameters except NVMe command data payload size:
Variable |
Value |
|---|---|
Tool and backend |
xnvmeperf + upcie-cuda |
Queue depth |
128 |
Number of CPU threads |
1 |
Number of devices |
4 |
I/O size |
{ 512, 4096, 8192 } |
Four devices were selected to ensure that the PCIe link, rather than aggregate device capacity, is the binding constraint at large I/O sizes. The Samsung PM1753 is rated at 14.5 GB/s bandwidth, and four devices therefore provide up to 4 × 14.5 GB/s = 58 GB/s aggregate, which is sufficient to stress the PCIe Gen5 x16 link (64 GB/s line rate) rather than leave it underutilized.
Metrics Collected#
Metric |
Reported by |
|---|---|
Payload bandwidth (GB/s) |
xnvmeperf |
Total PCIe RX bandwidth (p95, bytes/s) |
DCGM field 1010 via |
Peak P2P bidirectional bandwidth (GB/s) |
|
DCGM field 1010 counts PCIe receive bytes per second at the GPU endpoint, capturing all PCIe traffic directed to the GPU including NVMe payload, NVMe Submission Queue Entries, Completion Queue Entries, and PRP list transfers. The p95 is taken over 100 ms samples collected during the benchmark run. xnvmeperf reports payload bytes per second based on completed I/O operations and their requested sizes.
p2pBandwidthLatencyTest from the CUDA samples suite runs a sustained
bidirectional P2P bandwidth test between two GPUs. The value recorded is the mean
of the per-direction bandwidth measured simultaneously in both directions.
Environment#
The benchmarks were run on the High-Performance Compute Server. NVMe devices are bound to
user space drivers. The CPU governor is set to performance with turbo boost and
SMT enabled. Each configuration is run five times and results are reported as
arithmetic means.
Execution of the Experiment#
Instructions for running bench_pcie.yaml are provided in
Experimental Framework.
Results#
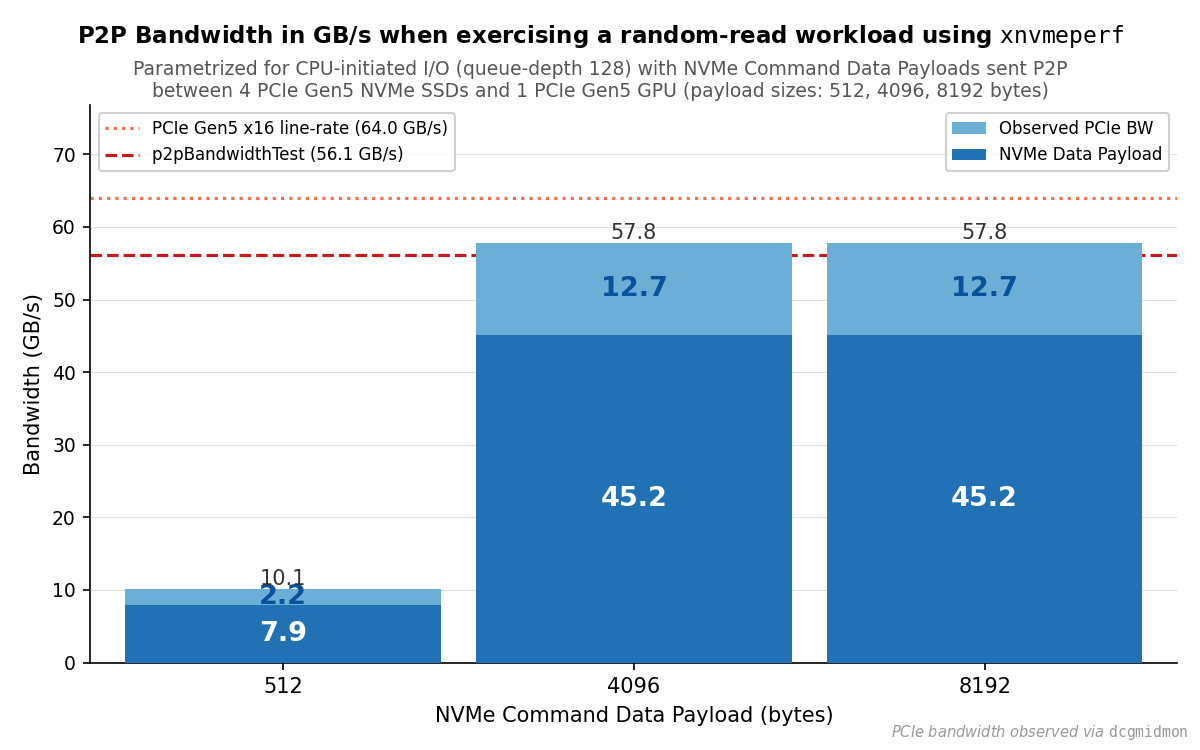
PCIe RX bandwidth by NVMe command data payload size, measured with 4 PCIe Gen5
NVMe SSDs transferring data P2P to a PCIe Gen5 GPU via the upcie-cuda backend.
Each bar is stacked: the lower segment is the payload bandwidth reported by
xnvmeperf; the upper segment is the remainder observed by DCGM. The dashed lines
mark the PCIe Gen5 x16 line rate (64.0 GB/s) and the reference P2P bandwidth from
p2pBandwidthLatencyTest (56.1 GB/s).#
Small I/O: Link Underutilized#
With 512-byte payloads, xnvmeperf reports 7.9 GB/s payload bandwidth and DCGM measures 10.1 GB/s total PCIe receive traffic, corresponding to approximately 16% of the PCIe Gen5 x16 line rate. This is consistent with the IOPS-bound regime observed in the software abstraction overhead results: at small I/O sizes the constraint is NVMe command throughput, not PCIe link capacity.
Large I/O: Link Approaches Saturation#
With 4096- and 8192-byte payloads, DCGM measures approximately 57.8 GB/s in both
cases, exceeding the p2pBandwidthLatencyTest reference of 56.1 GB/s and
reaching approximately 90% of the 64.0 GB/s line rate. The identical result at
both I/O sizes indicates that the PCIe link, rather than NVMe command throughput,
is the binding constraint at these I/O sizes. xnvmeperf reports approximately
45.2 GB/s of payload bandwidth for both sizes. This saturation is achieved
with a single CPU thread and only four NVMe devices, demonstrating that the
uPCIe-cuda path requires minimal CPU and device resources to fully utilize the
PCIe link at larger I/O sizes.
PCIe Protocol Overhead#
Across all three I/O sizes, the total PCIe receive bandwidth measured by DCGM exceeds the payload bandwidth reported by xnvmeperf by a consistent factor of approximately 1.28. The ratio holds across both the IOPS-bound regime at 512 bytes and the bandwidth-bound regime at 4096 and 8192 bytes, spanning a range where IOPS differ by an order of magnitude. This indicates that the excess scales with bytes transferred rather than with operation count, making the 28% overhead a stable characterization of the P2P data path regardless of operating regime.
Summary#
At small I/O sizes the P2P link operates far below capacity. At 4 KiB and above, a single CPU thread driving four NVMe devices is sufficient to push total PCIe traffic to approximately 57.8 GB/s, exceeding the practical P2P ceiling of 56.1 GB/s and reaching approximately 90% of the Gen5 x16 line rate. Protocol overhead accounts for a consistent 28% above payload bandwidth across all tested I/O sizes, indicating it scales with bytes transferred rather than operation count.