Device-initiated I/O: Queue Depth Scaling#
The previous experiment showed that at 512-byte I/O the PCIe link cannot be saturated regardless of thread count, and that the constraint is device IOPS, which was established to be 61.7 M IOPS in the CPU-initiated I/O: Optimal Parameter Search experiment. This experiment holds I/O size fixed at 512 bytes and sweeps queue depth across a wide range, with the number of queues per device as the secondary variable. The aim is to identify the queue depth at which each queue-count configuration saturates under device-initiated I/O.
xnvmeperf drives device-initiated I/O via the cuda-run subcommand
with the upcie-cuda backend. The subcommand distributes NVMe queues across
devices: with nqueues=N and 16 devices, each device is assigned N queue
pairs; each in-flight command is serviced by a dedicated CUDA thread. The total
thread count equals queue depth × nqueues × number of devices. Increasing
either dimension raises both the thread count and the number of commands in
flight. The experiment sweeps both dimensions to identify which combination
first reaches device saturation.
Independent Variables#
Variable |
Parameter Set |
|---|---|
Queue depth |
{ 1, 2, 4, 8, 16, 32, 64, 128, 256, 512 } |
Number of queues |
{ 1, 2, 4, 8, 16 } |
I/O size |
512 |
Number of devices |
16 |
Tool and backend |
xnvmeperf (cuda-run) + upcie-cuda |
Metrics Collected#
Metric |
Reported by |
|---|---|
Completed IOPS |
xnvmeperf |
Environment#
The benchmarks were run on the High-Performance Compute Server. NVMe devices are bound
to user space drivers. The CPU governor is set to performance with turbo
boost and SMT enabled. Each configuration is run five times and results are
reported as arithmetic means.
Execution of the Experiment#
Instructions for running bench_cuda_qdepth.yaml are provided in
Experimental Framework.
Results#
Results are presented as IOPS vs. queue depth, with one line per number of
queues (nqueues ∈ { 1, 2, 4, 8, 16 }). All configurations use xnvmeperf
with the cuda-run subcommand and the upcie-cuda backend, 16 NVMe
devices, and 512-byte I/O.
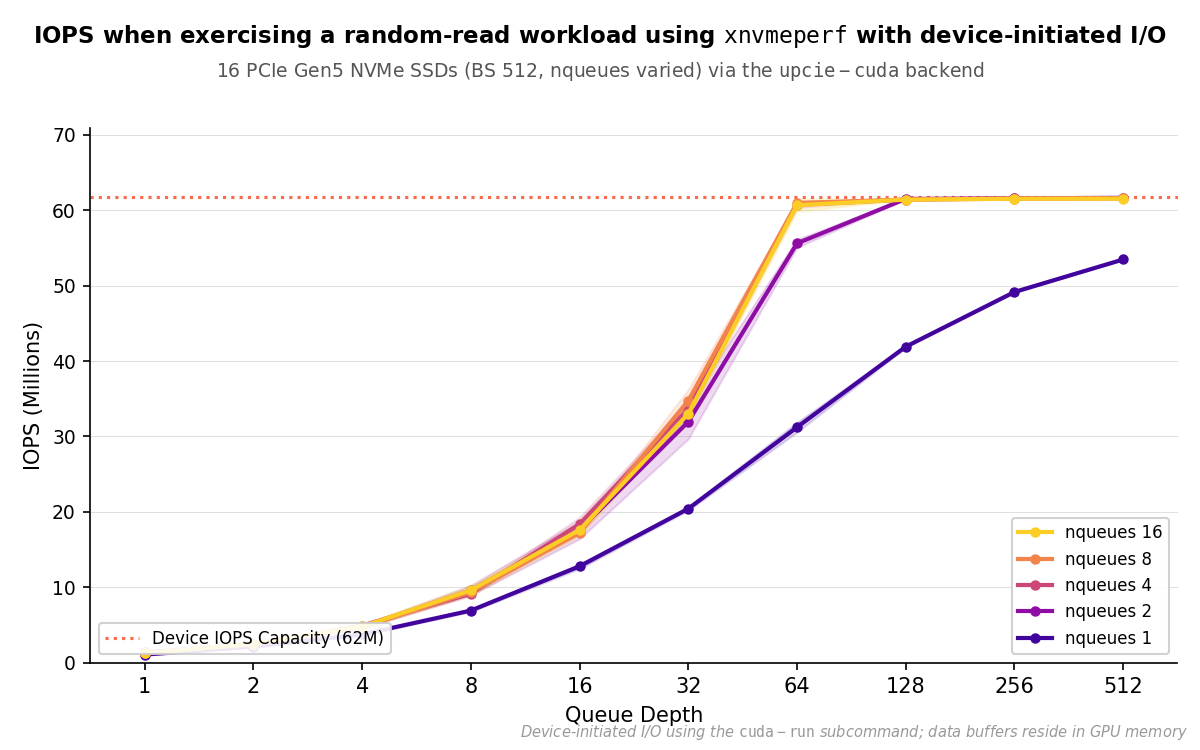
IOPS vs. queue depth for xnvmeperf (cuda-run), 16 NVMe devices, 512 B I/O. All nqueues ≥ 2 configurations reach the 61.7 M IOPS roofline at qdepth=128; nqueues=1 reaches only 86.6% (53.5 M IOPS) at qdepth=512.#
The results reveal a sharp divide between single-queue and multi-queue
operation. With nqueues=1, IOPS scales sub-linearly with queue depth and
fails to saturate the device even at qdepth=512 (53.5 M IOPS, 86.6% of the
61.7 M roofline). All multi-queue configurations (nqueues ≥ 2) saturate the
device completely, converging to ~61.5 M IOPS with very low variance once the
threshold queue depth is reached. At qdepth=128, nqueues=2 delivers 61.5
M IOPS. This is a 47% gain over the 41.9 M achieved by nqueues=1 at the same
depth. Further queue doublings yield no measurable improvement.
The minimum queue depth required to saturate the device varies by nqueues:
|
Min. |
Total CUDA threads |
|---|---|---|
1 |
> 512 (not reached) |
> 8192 |
2 |
128 |
4096 |
4 |
64 |
4096 |
8 |
64 |
8192 |
16 |
64 |
16384 |
Total CUDA thread count is qdepth × nqueues × ndevs (16 devices).
nqueues=2 and nqueues=4 are equally thread-efficient, both saturating
the device at 4096 total threads. nqueues=8 and nqueues=16 reach
the roofline at the same qdepth=64 but require 2× and 4× as many threads
respectively for no throughput gain, making them suboptimal.
nqueues=4 with qdepth=64 represents the most practical configuration:
it saturates the device at 4096 total threads, matching nqueues=2 at
qdepth=128, while requiring only half the per-queue depth, halving the
number of commands in flight per queue.
Summary#
A single queue per device cannot saturate the devices at 512-byte I/O regardless
of queue depth. Adding a second queue breaks this ceiling: nqueues=2 with
qdepth=128 reaches the 61.7 M IOPS roofline at 4096 total threads, and
nqueues=4 with qdepth=64 matches this result with half the per-queue
depth. Beyond nqueues=4, additional queues increase thread count without
improving throughput. Together with the I/O size scaling results, these findings
characterize the thread count and queue configuration required to fully utilize
device-initiated I/O across both the bandwidth-bound and IOPS-bound regimes.